本文介绍了 MySQL 中的常用数据类型及其适用场景,以及数据库范式和反范式化的设计。
1、MySQL 常用数据类型
MySQL 常用数据类型分为:整数、实数、字符串、日期和时间、位数据几种。
整数类型
整数类型可以分为:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT,分别使用:8,16,24,32,64 位的存储空间。
整数类型有可选的 UNSIGNED 属性,表示不允许负值,可以把正数的上限提高一倍。
整数可以指定宽度,比如 INT(11),这表示在一些交互工具中 INT 会显示 11 个数字,对于存储和计算来说没有意义,INT(1) 和 INT(20) 都是 32 位。
实数类型
实数类型可以是带有小数部分的数字,也可以不是。比如可以使用 DECIMAL 存储比 BIGINT 还大的整数。
实数类型分为:FLOAT,DOUBLE 和 DECIMAL,其中 FLOAT 和 DOUBLE 用于存储不精确的小数类型,分别使用 32 和 64 位的存储空间;DECIMAL 用于存储精确的小数类型,存储空间的大小根据小数的长度决定。5.0 版本以后 DECIMAL 最多允许 65 个数字。
尽量使用 FLOAT 和 DOUBLE 存储小数类型。只有需要精确计算的场合才使用 DECIMAL,但在数据量比较大的时候,可以考虑使用 BIGINT 代替 DECIMAL,将需要存储的数字乘以相应的倍数即可。
字符串类型
MySQL 中的字符串类型有 CHAR,VARCHAR,TEXT 和 BLOB 四种,其中 TEXT 和 BLOB 两种类型比较特别,MySQL 把每个 BLOB 和 TEXT 值当作一个独立的对象处理,存储引擎在处理时也通常会做相应的处理。比如当 TEXT 或 BLOB 的值较大时,innodb 会使用专门的“外部”存储区域来进行存储,此时每个值在行内需要 1~4 个字节存储一个指针。
TEXT 和 BLOB 之间仅有的不同是 BLOB 类型存储的是二进制数据,没有排序规则或字符集,而 TEXT 类型有字符集和排序规则。
MySQL 对 BLOB 和 TEXT 列进行排序与其他类型是不同的:它只对每个列的最前 max_sort_length 字节而不是整个字符串做排序。
VARCHAR 是变长字符串,而 CHAR 是定长字符串。VARCHAR 比 CHAR 更省空间,因为它仅使用必要的空间。VARCHAR 需要使用 1 或 2 个额外字节记录字符串的长度:如果列的最大长度小于或等于 255 字节,则只使用 1 个字节表示,否则使用 2 个。
VARCHAR 节省了存储空间,但由于行是变长的,在 UPDATE 时可能使行变得比原来更长,这就导致需要做额外的工作。如果一个行占用空间增长,超出页的大小,innodb 会使用裂页来使行可以放进页内。对于过长的 VARCHAR,innodb 会将其存储为 BLOB。
CHAR 值在存储时,MySQL 会删除所有的末尾空格。
使用枚举(ENUM)代替字符串类型
如果预计字符串可取的值范围确定且数量不大,可以使用枚举的方式替代字符串。比如存储水果,预计种类只有苹果、香蕉、梨。可以把水果种类定义为 ENUM(“apple”,”banana”,”pear”),实际存储时 MySQL 只会在列表中保存数字,并在.frm 文件中保存一个“数字-字符串”的映射关系,可以大大减少存储的空间。
日期和时间类型
MySQL 能存储的最小时间粒度为秒,但也可以通过使用 BIGINT 类型存储微秒级别的时间戳等方式绕开这一限制。MySQL 中存储时间的数据类型有两种:DATETIME 和 TIMESTAMP。两种类型的区别如下:
DATETIME
- 占用 8 个字节
- 允许为空值,可以自定义值,系统不会自动修改其值。
- 实际格式储存,格式为 YYYYMMDDHHMMSS 的整数
- 与时区无关
- 不可以设定默认值,所以在不允许为空值的情况下,必须手动指定 datetime 字段的值才可以成功插入数据。
- 可以在指定 datetime 字段的值的时候使用 now() 变量来自动插入系统的当前时间。
结论:datetime 类型适合用来记录数据的原始的创建时间,因为无论你怎么更改记录中其他字段的值,datetime 字段的值都不会改变,除非你手动更改它。
TIMESTAMP
- 占用 4 个字节,默认为 NOT NULL
- TIMESTAMP 值不能早于 1970 或晚于 2037。这说明一个日期,例如 ‘1968-01-01’,虽然对于 DATETIME 或 DATE 值是有效的,但对于 TIMESTAMP 值却无效,如果分配给这样一个对象将被转换为 0。
- 值以 UTC 格式保存,为从 1970 年 1 月 1 日(格林尼治时间)午夜以来的秒数。
- 时区转化 ,存储时对当前的时区进行转换,检索时再转换回当前的时区。
- 默认情况下,如果插入或更新时没有指定第一个 TIMESTAMP 的值,MySQL 会设置这个列的值为当前时间。
结论:timestamp 类型适合用来记录数据的最后修改时间,因为只要你更改了记录中其他字段的值,timestamp 字段的值都会被自动更新。
位数据类型
BIT 和 SET 是 MySQL 中典型的位数据类型,位数据的本质是一个二进制字符串,使用位数据类型可以在一列中存储多个”true/false”值。
2、范式和反范式
数据库中的范式
满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式 (3NF)就行了。
范式的包含关系。一个数据库设计如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式。
- 1NF:属性不可分
- 2NF:属性完全依赖于主键 [消除部分子函数依赖 ]
- 3NF:属性不依赖于其它非主属性 [消除传递依赖 ]
第一范式 (1NF)
符合 1NF 的关系中的每个属性都不可再分。
反例: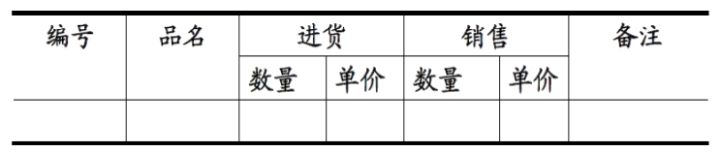
第二范式 (2NF)
2NF 在 1NF 的基础之上,消除了非主属性对于码(主键)的部分函数依赖
可以通过分解来满足。
分解前
| 学号 | 姓名 | 系名 | 系主任 | 课名 | 分数 |
|---|---|---|---|---|---|
| 1022211101 | 李小明 | 经济系 | 王强 | 高等数学 | 95 |
| 1022211101 | 李小明 | 经济系 | 王强 | 大学英语 | 87 |
| 1022211101 | 李小明 | 经济系 | 王强 | 普通化学 | 76 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 高等数学 | 72 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 大学英语 | 98 |
| 1022211102 | 张莉莉 | 经济系 | 王强 | 计算机基础 | 88 |
| 1022511101 | 高芳芳 | 法律系 | 刘玲 | 高等数学 | 82 |
| 1022511101 | 高芳芳 | 法律系 | 刘玲 | 法律基础 | 82 |
以上学生课程关系中,{学号, 课名} 为键码(主键),有如下函数依赖:
- (学号,课名) -> 分数
- 学号 -> 姓名
- 学号 -> 系名 -> 系主任
分数完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
姓名、系名和系主任都部分依赖于键码,我们需要把部分依赖变成完全依赖。
分解后
关系-1
| 学号 | 姓名 | 系名 | 系主任 |
|---|---|---|---|
| 1022211101 | 李小明 | 经济系 | 王强 |
| 1022211102 | 张莉莉 | 经济系 | 王强 |
| 1022211101 | 高芳芳 | 法律系 | 刘玲 |
有以下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
关系-2
| 学号 | 课名 | 分数 |
|---|---|---|
| 1022211101 | 高等数学 | 95 |
| 1022211101 | 大学英语 | 87 |
| 1022211101 | 普通化学 | 76 |
| 1022211102 | 高等数学 | 72 |
| 1022211102 | 大学英语 | 98 |
| 1022211102 | 计算机基础 | 88 |
| 1022511101 | 高等数学 | 82 |
| 1022511101 | 法学基础 | 82 |
有以下函数依赖:
- Sno, Cname -> Grade
第三范式 (3NF)
3NF 在 2NF 的基础之上,消除了非主属性对于码(主键)的传递函数依赖
上面的 关系-1 中存在以下传递函数依赖:
- Sno -> Sdept -> Mname
可以进行以下分解:
关系-11
| 学号 | 姓名 | 系名 |
|---|---|---|
| 1022211101 | 李小明 | 经济系 |
| 1022211102 | 张莉莉 | 经济系 |
| 1022211101 | 高芳芳 | 法律系 |
关系-12
| 系名 | 系主任 |
|---|---|
| 经济系 | 王强 |
| 法律系 | 刘玲 |
范式的优缺点
优点:
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以更新时只需要修改更少的数据。
- 范式化的表通常更小,可以更好地放在内存里,所以执行操作很更快。
- 很少有多余的数据意味着检索列表数据时更少需要 DISTINCT 或者 GROUP BY 语句。比如前面的例子:在非范式化的结构中必须使用 DISTINCT 或者 GROUP BY 才能获得唯一的一张系名列表,但如果使用范式,只需要单独查询系名-系主任表就可以了。
缺点:
- 范式化的设计通常需要关联。稍微复杂一点的查询语句在符合范式的 schema 上都有可能需要至少一次关联,这不但代价昂贵,也可能使一些索引无效。例如,范式化可能将列存放在不同的表中,而这些列如果在一个表中本可以属于同一个索引。
常见反范式化设计
范式化不一定适合所有场合,很多时候,一些冗余数据有助于我们提升性能。下面列举几个常见的反范式化操作。
缓存表
缓存表可以存储那些可以从其他表获取但每次获取的速度比较慢的数据。比如有时可能会需要很多不同的索引组合来加速各种类型的查询。这些矛盾的需求有时需要创建一张只包含主表中部分列的缓存表。有时候我们可能需要不同存储引擎提供的不同特性。例如,如果主表使用 innodb,用 MyISAM 作为缓存表的引擎将会得到更小的索引空间,并且可以做全文索引。
汇总表
汇总表保存的是 GROUP BY 语句聚合数据的表。相比缓存表,汇总表的数据不是逻辑上冗余的,但可以通过其它表计算得到。例如,计算某网站之前 24 小时内发送的消息数。我们可以通过 COUNT() 得到,但这样需要检索全表。作为替代方案,可以每小时生成一张汇总表。这样也许一条简单的查询就可以做到,并且比实时维护计数器要高效得多。缺点是计数并不是 100% 精确。
某网站之前 24 小时内发送的消息数的汇总表:
CREATE TABLE msg_per_hr (
hr DATETIME NOT NULL,
cnt INT UNSIGNED NOT NULL,
PRIMARY KEY(hr)
);
计数器表
计数器在应用中很常见。比如网站的点击数,文件下载次数等。 如果其它数据保存在一起,很可能碰到并发问题。创建一张独立的表是个比较好的办法,这样可使计数器表小且快。而且使用独立的表可以帮助避免查询缓存失效。
下面是一张简单的计数器表,只有一行数据,记录网站的点击次数:
mysql> CREATE TABLE hit_counter(
-> cnt int unsigned not null
-> ) ENGINE=InnoDB;
网站的每次点击都会导致对计数器进行更新:
mysql> UPDATE hit_counter SET cnt = cnt + 1;
问题在于,对于任何想要更新这一行的事务来说,这条记录上都有一个全局的互斥锁。这会使得这些事务只能串行进行。要获得更高的并发性,可以将计数器保存在多个行中,每次随机选择一行更新:
mysql> CREATE TABLE hit_counter(
-> slot tinyint unsigned not null primary key,
-> cnt int unsigned not null
-> ) ENGINE=InnoDB;
然后预先在这张表增加 100 行数据。现在选择一个随机的槽进行更新:
mysql> UPDATE hit_counter SET cnt = cnt + 1 WHERE slot = RAND() * 100;
要获得统计结果,需要使用下面这样的聚合查询:
mysql> CREATE TABLE daily_hit_counter(
-> day date not null,
-> slot tinyint unsigned not null,
-> cnt int unsigned not null,
-> primary key(day, slot)
-> ) ENGINE=InnoDB;
一个常见的需求是每隔一段时间开始一个新的计算器(例如,每天一个)。再作进一步修改:
mysql> CREATE TABLE daily_hit_counter(
-> day date not null,
-> slot tinyint unsigned not null,
-> cnt int unsigned not null,
-> primary key(day, slot)
-> ) ENGINE=InnoDB;
在这个场景中可以不用预告生成行 ,而用 ON DUPLICATE KEY UPDATE(对唯一索引或主键字段的值会检查是否已存在,存在则更新,不存在则插入)代替:
mysql> INSERT INTO daily_hit_counter(day, slot, cnt)
-> VALUES(CURRENT_DATE, RAND()*100, 1)
-> ON DUPLICATE KEY UPDATE cnt = cnt + 1;
如果希望减少表的行数,可以写一个周期执行的任务,合并所有结果到 0 号槽,并且删除所有其他的槽:
UPDATE daily_hit_counter as c
-> INNER JOIN (
-> SELECT day, SUM(cnt) AS cnt, MIN(slot) AS mslot
-> FROM daily_hit_counter
-> GROUP BY day
-> ) AS X USING(day)
-> SET c.cnt = IF(c.slot = x.mslot, x.cnt, 0),
-> c.slot = IF(c.slot = x.mslot, 0, c.slot);
mysql> DELETE FROM daily_hit_counter WHERE slot <> 0 AND cnt = 0;