NIO(Non-blocking I/O),是一种同步非阻塞的 I/O 模型,也是 I/O 多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O 处理问题的有效方式。Java 中的 NIO 是 jdk 1.4 之后新出的一套 IO 接口,相比传统 IO(BIO),两者有如下区别:
- IO 是面向流的,NIO 是面向缓冲区的
- IO 流是同步阻塞的,NIO 流是同步非阻塞的
- NIO 有选择器(Selector),IO 没有
- IO 的流是单向的,NIO 的通道(Channel)是双向的
IO 基本概念
Linux 的内核将所有外部设备都可以看做一个文件来操作。那么我们对与外部设备的操作都可以看做对文件进行操作。我们对一个文件的读写,都通过调用内核提供的系统调用;内核给我们返回一个 file descriptor(fd,文件描述符)。对一个 socket 的读写也会有相应的描述符,称为 socketfd(socket 描述符)。描述符就是一个数字 (可以理解为一个索引),指向内核中一个结构体(文件路径,数据区,等一些属性)。应用程序对文件的读写就通过对描述符的读写完成。
一个基本的 IO,它会涉及到两个系统对象,一个是调用这个 IO 的进程对象,另一个就是系统内核 (kernel)。当一个 read 操作发生时,它会经历四个阶段:
- 1、通过 read 系统调用想内核发起读请求。
- 2、内核向硬件发送读指令,并等待读就绪。
- 3、内核把将要读取的数据复制到描述符所指向的内核缓存区中。
- 4、将数据从内核缓存区拷贝到用户进程空间中。
同步和异步
同步和异步关注的是消息通信机制 (synchronous communication / asynchronous communication)
。所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。 而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞和非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态。阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。 非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
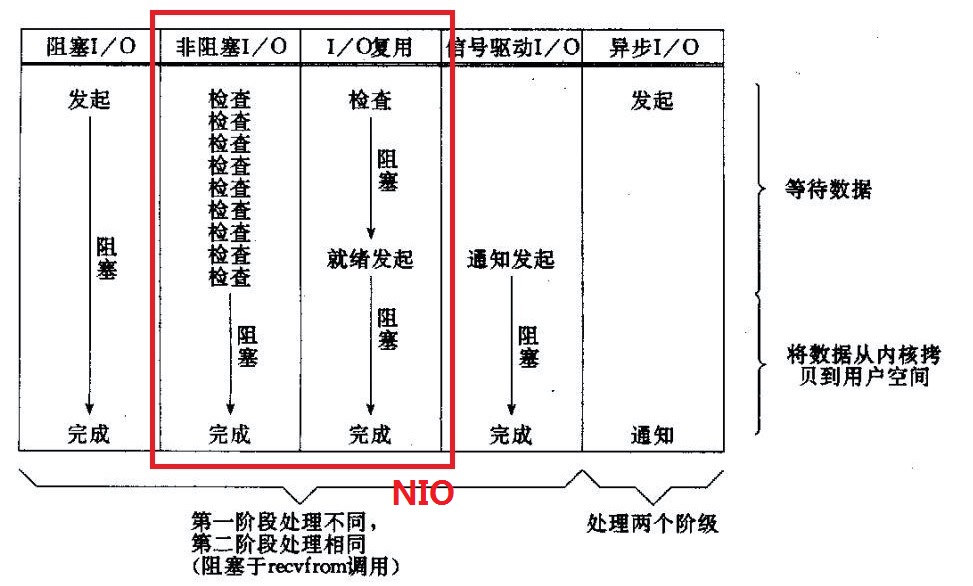
常见 I/O 模型对比
所有的系统 I/O 都分为两个阶段:等待就绪和操作。举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。需要说明的是等待就绪的阻塞是不使用 CPU 的,是在“空等”;而真正的读写操作的阻塞是使用 CPU 的,真正在”干活”,而且这个过程非常快,属于 memory copy,带宽通常在 1GB/s 级别以上,可以理解为基本不耗时。
以 socket.read() 为例子:传统的 BIO 里面 socket.read(),如果 TCP RecvBuffer 里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。对于 NIO,如果 TCP RecvBuffer 有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回 0,永远不会阻塞。最新的 AIO(Async I/O) 里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。换句话说,BIO 里用户最关心“我要读”,NIO 里用户最关心”我可以读了”,在 AIO 模型里用户更需要关注的是“读完了”。NIO 一个重要的特点是:socket 主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的 I/O 操作是同步阻塞的(消耗 CPU 但性能非常高)。
传统 BIO 模型分析
了解 NIO 就要从传统 BIO 的弊端说起。
在传统的 BIO 中,一旦用户线程发起 IO 请求,则必须要等内核将数据报准备好,才能将数据从内核复制到用户空间。这是一种效率很低的方式。传统的 BIO 一般要配合线程池来使用,我们的编程范式(伪代码)一般是这样的:
1 | ExecutorService executor = Excutors.newFixedThreadPollExecutor(100); // 线程池 |
这是一个经典的每连接每线程的模型,之所以使用多线程,主要原因在于 socket.accept()、socket.read()、socket.write() 三个主要函数都是同步阻塞的,当一个连接在处理 I/O 的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但 CPU 是被释放出来的,开启多线程,就可以让 CPU 去处理更多的事情。其实这也是所有使用多线程的本质:
- 利用多核。
- 当 I/O 阻塞系统,但 CPU 空闲的时候,可以利用多线程使用 CPU 资源。
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
- 线程的创建和销毁成本很高,在 Linux 这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像 Java 的线程栈,一般至少分配 512K~1M 的空间,如果系统中的线程数过千,恐怕整个 JVM 的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统 load 偏高、CPU sy 使用率特别高(超过 20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或 CPU 核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的 I/O 处理模型。
NIO 是如何工作的
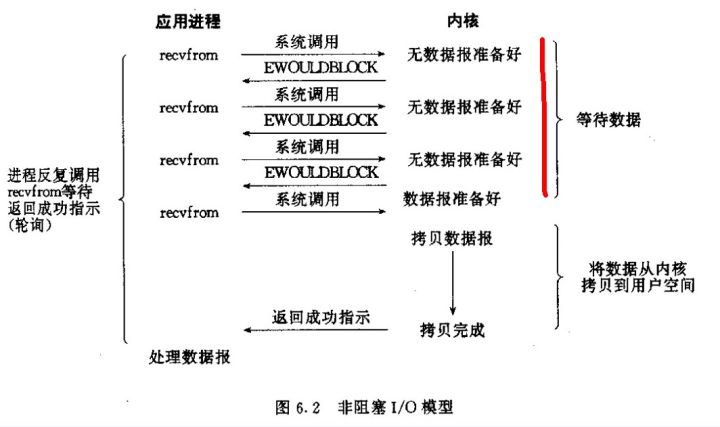
这是一个 NIO 基本的工作方式(但不常用),我们把一个套接口设置为非阻塞,当所请求的 I/O 操作不能满足要求时候,不把本进程投入睡眠,而是返回一个错误。也就是说当数据没有到达时并不等待,而是以一个错误返回。
事件驱动的 I/O 复用模型(常用)
在 BIO 的场景下,为了避免线程长时间阻塞在等待内核准备上,我们选择了每连接每线程的方式。但在 NIO 的场景下,如果当前的连接没有准备好,可以选择下一个连接。比如我们的聊天程序,我们可以建立两个连接:一个发送端,一个接收端。程序会不断轮询这两个连接,如果接收端有数据达到,那就把它显示在屏幕上;如果发送端有数据发出,那就把它发出。但如果接收端没有数据,或者发送端的网卡没有准备好,程序也不会停下来,而是继续轮询,直到有一方准备好。这种一个进程/线程处理多个 IO 的方式,被称为 I/O 复用模型。
而如果我们把发送就绪和接收就绪当成两类事件,只有在这两类事件发生的时候才会触发轮询,其它时候(比如等待请求时),程序不会被唤醒,那么这种方式就被称为事件驱动。
Linux 中的 select,poll,epoll 是典型的事件驱动的 I/O 复用模型:
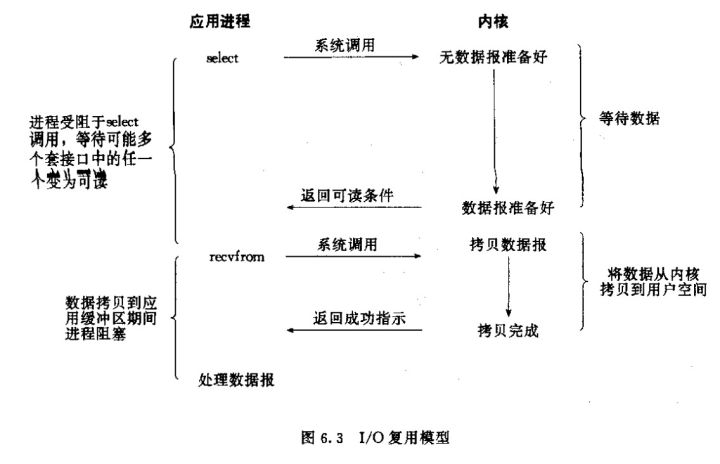
select() 会把所有的 I/O 请求封装为文件描述符 (fd) 的形式给操作系统,让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,以此来实现一个线程/进程管理多个 I/O 的功能。
poll() 在 select 上支持更多数量的 fd。因为 select 中使用数组形式存放文件描述符,数量有限(一般 1024 个),poll 使用链表的形式,理论上支持的描述符数量没有上限。
epoll() 在 select/poll 的基础上有了大幅改进:
- 它使用红黑树来存储所有需要查询的事件,事件的添加和删除对应红黑树的插入和删除,复杂度从 O(N) 降为了 O(logN)。
- 它使用双向链表来保存就绪的事件。所有添加到红黑树上的事件都会与设备 (网卡) 驱动程序建立回调关系,当相应的事件发生时会调用这个回调方法,回调方法会把事件放入双向链表中。
- 返回时返回的是就绪事件(双向链表)而不是所有事件,既减少了内核到用户空间的拷贝数据量,又省了用户程序筛选就绪事件的时间。
- 相比 select/poll 的水平触发模式,epoll 也支持边沿触发模式。即用户可以选择到底是接受所有就绪的事件(水平触发),还是只接受上次检查以后新就绪的事件(边沿触发)。
Java 中的 NIO 模型
Java 中的 NIO 模型选用了事件驱动的 I/O 复用模型。事实上,在 Linux 上 Java 的 NIO 就是基于 select,poll,epoll 来实现的(Linux 2.6 之前是 select、poll,2.6 之后是 epoll)。
在 Java 的 NIO 中,有 4 类事件:读就绪(OP_READ),写就绪(OP_WRITE),收到请求(仅服务端有效,OP_ACCEPT),发出请求(仅客户端有效,OP_CONNECT)。我们需要注册当这几个事件到来的时候所对应的处理器。然后在合适的时机告诉事件选择器:我对这个事件感兴趣。对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于 accept,一般是服务器刚启动的时候;而对于 connect,一般是 connect 失败需要重连或者直接异步调用 connect 的时候。新事件到来的时候,会在 selector 上注册标记位,标示可读、可写或者有连接到来。编程范式(伪代码)一般如下:
1 | //处理器抽象接口 |
Buffer 的选择
Java 中的 NIO 还有一个特点是面向缓冲区的。这一特性其实在传统 IO 中就有用到,这里不再赘述。但是 Buffer 的选择也是一个值得注意的地方。
通常情况下,操作系统的一次写操作分为两步: 1. 将数据从用户空间拷贝到系统空间。 2. 从系统空间往网卡写。同理,读操作也分为两步: ① 将数据从网卡拷贝到系统空间; ② 将数据从系统空间拷贝到用户空间。
对于 NIO 来说,缓存的使用可以使用 DirectByteBuffer 和 HeapByteBuffer。如果使用了 DirectByteBuffer,一般来说可以减少一次系统空间到用户空间的拷贝。但 Buffer 创建和销毁的成本更高,更不宜维护,通常会用内存池来提高性能。如果数据量比较小的中小应用情况下,可以考虑使用 heapBuffer;反之可以用 directBuffer。
使用 NIO != 高性能,当连接数 <1000,并发程度不高或者局域网环境下 NIO 并没有显著的性能优势。
NIO 并没有完全屏蔽平台差异,它仍然是基于各个操作系统的 I/O 系统实现的,差异仍然存在。使用 NIO 做网络编程构建事件驱动模型并不容易,陷阱重重。
推荐大家使用成熟的 NIO 框架,如 Netty,MINA 等。解决了很多 NIO 的陷阱,并屏蔽了操作系统的差异,有较好的性能和编程模型。
总结
最后总结一下 Java 中的 NIO 为我们带来了什么:
- 非阻塞 I/O,I/O 读写不再阻塞,而是返回 0
- 避免多线程,单个线程可以处理多个任务
- 事件驱动模型
- 基于 block 的传输,通常比基于流的传输更高效
- IO 多路复用大大提高了 Java 网络应用的可伸缩性和实用性